Serverless has been overhyped, overcriticised, and systematically misunderstood — sometimes by the same team in the same week. The founders who've seen an unexpectedly large AWS Lambda bill swear it off entirely. The engineers who've watched a startup scale to millions of users without touching a server config swear by it.
Both are right, in context. Serverless is a genuinely good fit for specific workload patterns and a genuinely bad fit for others. The teams that use it well understand exactly which is which.
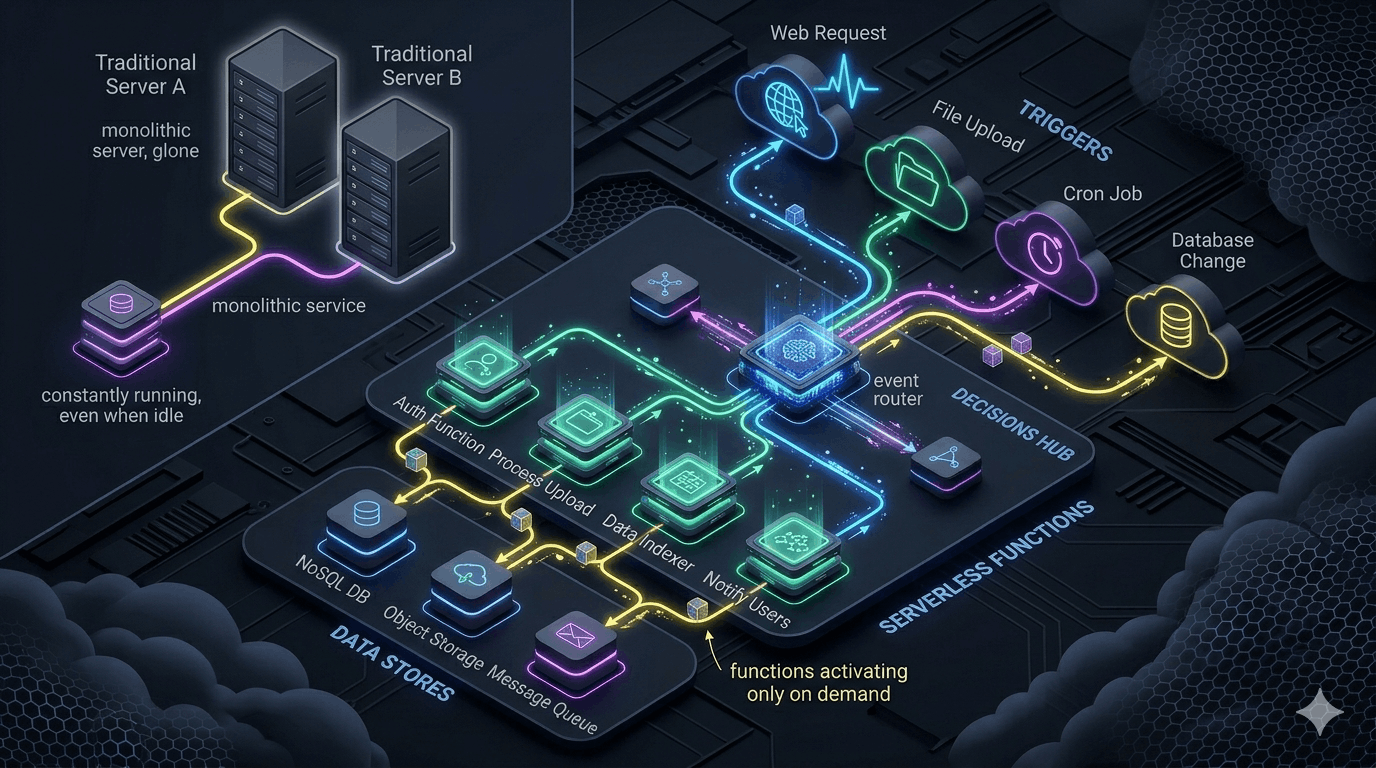
What serverless actually means
Serverless doesn't mean no servers. It means you don't manage them — you deploy functions or containers, and the cloud provider handles provisioning, scaling, and availability. You pay per invocation or per duration, not for idle capacity.
The key characteristics: near-infinite scale on demand, zero cost at zero traffic, no infrastructure management overhead, and cold start latency on first invocation after idle periods. Whether those characteristics are features or bugs depends entirely on your workload.
Where serverless wins clearly
⚡ Bursty, unpredictable workloads
Batch processing jobs that run once a day, webhook handlers that receive traffic in spikes, image processing triggered by uploads. These workloads spend most of their time at zero — paying for idle servers is waste. Serverless charges nothing for idle and scales instantly for the burst.
🔌 Event-driven background tasks
Database triggers, queue consumers, scheduled cron jobs, notification dispatch. Lambda, Cloud Functions, and Azure Functions were designed for exactly this — short-lived, stateless, invoked by events.
🚀 Early-stage products with uncertain scale
When you don't know whether you'll have 100 users or 100,000 next month, serverless removes the provisioning gamble. The infrastructure auto-calibrates.
🌐 Edge computing and CDN logic
Request/response transformation, A/B testing, authentication at the edge, geo-routing. Cloudflare Workers and Vercel Edge Functions add programmability to the CDN layer with near-zero latency globally.
Where serverless fails in practice
Latency-sensitive APIs with consistent traffic: Cold starts are the serverless tax. A Lambda function that hasn't been invoked in 5 minutes might take 500ms–1s to respond. For a checkout API or real-time search endpoint, that's a user-facing problem. Provisioned concurrency mitigates this but erodes the cost advantage.
Long-running processes: AWS Lambda caps execution at 15 minutes. If your workload takes longer — large file processing, complex data transformations, model inference on large inputs — you need a different compute model.
Stateful applications: Serverless functions are stateless by design. In-memory caching doesn't survive across invocations. If your application logic depends on local state, WebSocket connections, or in-process caches, serverless adds complexity rather than removing it.
High-volume workloads at scale: The per-invocation pricing that's cheap at low volume becomes expensive at massive scale. At tens of millions of invocations per day, reserved EC2 instances or container clusters often win. Run the numbers for your actual traffic pattern.
Cold start mitigation strategies
Provisioned concurrency: Pre-warms a specified number of function instances so they're always ready. Eliminates cold starts for those instances. Cost: you pay for pre-warmed instances continuously, eroding the pay-per-use advantage. Use selectively for latency-sensitive functions.
Minimise package size: Cold start duration scales with package size. Avoid heavy SDK imports you don't need, use tree-shaking, and import only specific clients you use from AWS SDK v3 rather than the entire SDK.
Move initialisation outside the handler: Database connections, SDK clients, and config loading should happen at module level — once per container lifecycle — not inside the handler on every invocation.
// Bad: re-initialises on every invocation
export const handler = async (event) => {
const db = new DatabaseClient(process.env.DATABASE_URL); // Every call
return db.query(...);
};
// Good: initialises once per container
const db = new DatabaseClient(process.env.DATABASE_URL); // Once
export const handler = async (event) => {
return db.query(...); // Reuses existing connection
};Observability challenges in serverless
Standard APM agents don't work in serverless environments. There's no persistent process to instrument. Logs are ephemeral and split across invocations. Distributed traces span Lambda functions, API Gateway, SQS, and other managed services.
Structured logging is non-negotiable: Every log line needs invocation ID, function name, and relevant business context as structured JSON. CloudWatch Logs Insights can query structured logs across invocations — unstructured logs become unsearchable at scale.
AWS Lambda Powertools: Available for Python, TypeScript, Java, and .NET, Powertools provides structured logging, tracing, and metrics instrumentation designed specifically for Lambda. It handles correlation IDs, cold start tracking, and log level management. We use it on every Lambda-heavy project.
Custom business metrics: CloudWatch Lambda metrics tell you invocation count and duration. They don't tell you how many invoices were processed or how many payments failed. Emit custom CloudWatch metrics or push to your metrics platform for business-level observability alongside infrastructure metrics.
Local development workflow
AWS SAM local:
sam local invoke
and
sam local start-api
provide local Lambda execution environments that more closely
approximate the AWS runtime. Not perfect fidelity, but much better
than deploying to test.
LocalStack: Runs a local mock of AWS services — S3, SQS, DynamoDB, SNS — in Docker. Enables end-to-end local testing of serverless workflows without AWS API calls or cost. Particularly valuable for testing event-driven workflows where the trigger is an SQS message or S3 event.
Test business logic independently of the handler: Write your business logic as pure functions with no Lambda-specific dependencies, and keep the handler thin. Unit test the logic directly. This eliminates most local-vs-cloud fidelity concerns because the valuable tests don't touch the Lambda runtime at all.
The architecture pattern we use most
We rarely deploy products that are entirely serverless or entirely server-based. The pattern that works: always-on containerised servers for latency-sensitive endpoints and stateful logic, with serverless functions handling event-driven background work.
Your checkout API runs on an always-on container. Your post-purchase email dispatch runs on Lambda. Your nightly reporting job runs on a scheduled function. Your image resizing pipeline runs on Lambda triggered by S3 events. The compute model matches the workload pattern.
The cost conversation founders need to have earlier
Serverless cost surprises almost always come from one of two places: unexpectedly high invocation volume (a webhook that fires on every event including noise), or a tight loop where one invocation triggers another.
Set up billing alerts before you ship anything serverless to production. Not after. A runaway Lambda loop can generate a four-figure bill in hours — and AWS is under no obligation to refund it.
Vendor lock-in: the realistic assessment
The function code itself is typically portable. A Node.js Lambda function and a Cloud Functions function have different handler signatures, but the business logic inside is identical. What actually creates lock-in: cloud-specific event formats embedded in your business logic, and heavy reliance on proprietary managed services.
The practical mitigation: keep cloud-specific code at the edges. Lambda handlers should be thin adapters. Business logic lives in framework-agnostic functions. Infrastructure is in Terraform or CDK, not manual console setups. Migration becomes a week of work, not a multi-month rewrite.
The honest take
Serverless is excellent infrastructure that the industry managed to make controversial by overpromising. It doesn't eliminate operational concerns — it trades infrastructure management for invocation cost management, cold start handling, and distributed tracing complexity.
Used where it fits, it's genuinely one of the most cost-effective and low-maintenance compute options available. Used where it doesn't fit, it creates performance problems and surprise bills. The decision framework above is the one we walk through before every deployment.
