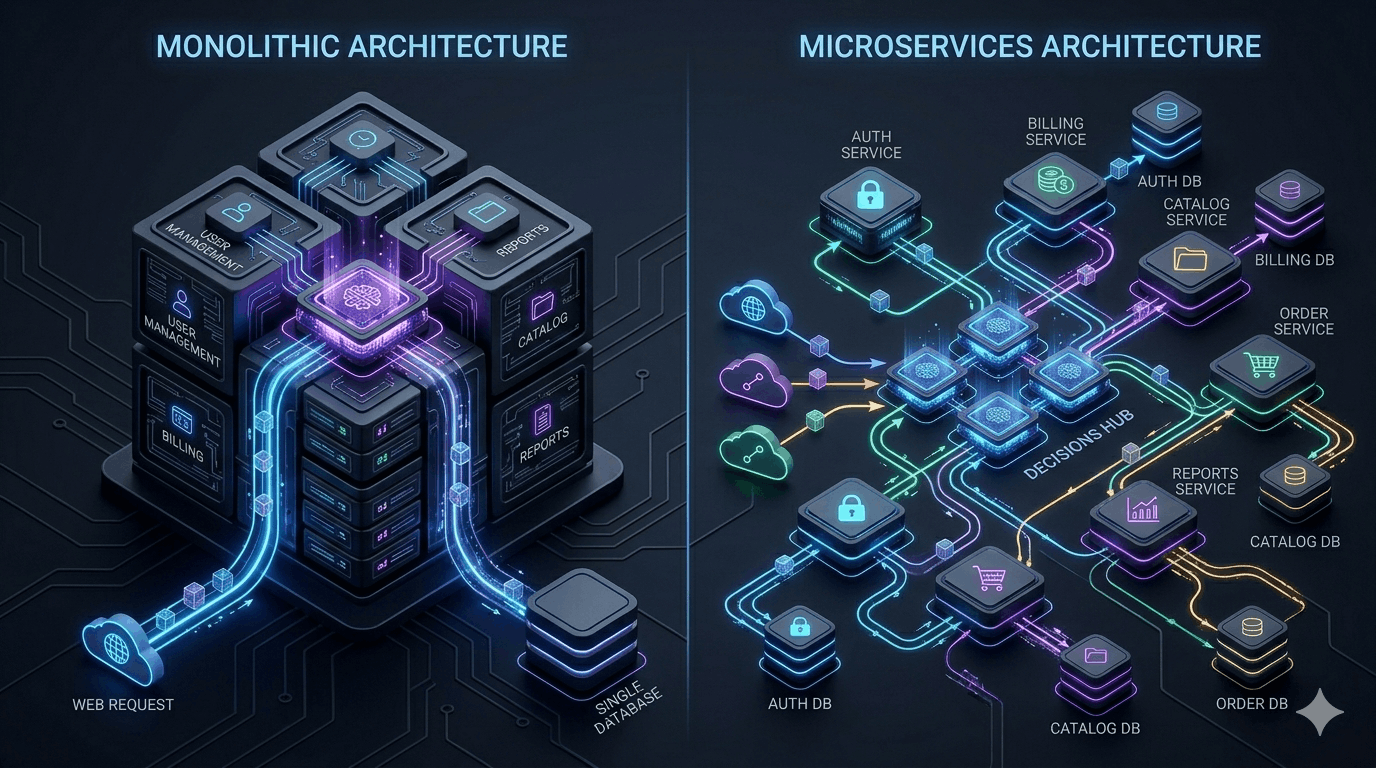
The microservices conversation usually goes one of two ways. Either a founder has read that Netflix uses microservices and assumes that's what serious companies do. Or an engineering team has inherited a distributed system that's become a maintenance nightmare and wants to burn it down.
Both perspectives miss the real question. Microservices vs. monolith is not an ideology — it's an engineering decision with specific trade-offs that depend entirely on where you are, how big your team is, and what problems you're actually trying to solve.
What a monolith actually is — and isn't
A monolith doesn't mean spaghetti code. It means a single deployable unit. You can have a beautifully modular, well-organised codebase that deploys as one service. The modularity is internal; the deployment boundary is external.
Modular monoliths — codebases with clear internal domain boundaries, shared nothing between modules except defined interfaces — give you most of the organisational benefits of microservices without the operational complexity. This is the architecture we recommend for the majority of early-stage products.
The real cost of microservices that nobody tells you
🌐 Network becomes a failure mode
In a monolith, a function call never fails due to latency or network partitions. In a distributed system, every service boundary is a potential failure point. You need retry logic, circuit breakers, and distributed tracing — infrastructure that doesn't exist in a monolith.
🔄 Distributed transactions are genuinely hard
Updating two services atomically requires either a two-phase commit or eventual consistency with compensation logic. In a monolith, it's a database transaction. This is a class of bug that takes senior engineers weeks to get right.
📦 Deployment complexity multiplies
Ten services means ten deployment pipelines, ten sets of environment variables, ten things that can fail during a release. Service mesh, container orchestration, service discovery — the operational surface area grows with every service you add.
👥 You need the team to justify it
Microservices are an organisational tool as much as a technical one. They make sense when different teams own different services and need to deploy independently. With a team of four engineers, the coordination overhead costs more than the independence gains.
When microservices are the right call
There are genuine cases where microservices are the correct architecture. The signal we look for: independent scaling requirements, team ownership boundaries, or genuinely different non-functional requirements between components.
Independent scaling: If your image processing service needs 50x more compute than your auth service during peak load, deploying them together forces you to over-provision everything. This is a real reason to separate them.
Team autonomy at scale: When you have 6+ teams and independent deployments matter for velocity, service boundaries that map to team ownership reduce coordination overhead. Conway's Law works in your favour.
Different technology requirements: Your ML inference service runs Python. Your API gateway runs Go. Your real-time messaging layer runs Elixir. These legitimately need to be separate services.
Service communication: synchronous vs asynchronous
How services talk to each other is a more consequential decision than how many services you have. Get it wrong and you've traded monolith coupling for distributed coupling — all the complexity, none of the independence.
Synchronous (HTTP/gRPC): Service A calls Service B and waits for a response. Simple to reason about. The problem: Service A now depends on Service B's availability. A 5% error rate in three sequential services becomes ~15% compounded.
Asynchronous (message queues): Service A publishes an event and continues. Service B processes it when ready. Services are temporally decoupled — B can be down for 10 minutes and catch up when it restarts. The trade-off: eventual consistency and more complex debugging.
| Use case | Communication pattern |
|---|---|
| User login — need auth token immediately | Synchronous (HTTP) |
| Order placed — trigger fulfilment, notify warehouse, send email | Async (message queue, fan-out) |
| Fetch product details for checkout page | Synchronous (HTTP or gRPC) |
| Payment processed — update inventory, generate invoice | Async (event-driven) |
| Real-time stock check during checkout | Synchronous |
| Post-order analytics and reporting | Async |
Data ownership between services
Each service owns its data. No service reads directly from another service's database. The rule is simple to state and difficult to enforce.
Why it matters: if Service A queries Service B's database directly, you've created invisible coupling. Schema changes in B silently break A. B can't evolve its data model without coordinating with every service that queries it. The independence you built microservices to achieve evaporates.
The enforcement mechanisms: separate databases per service (or separate schemas with no cross-schema queries). API contracts as the only interface — services expose data through APIs, not shared database access. Event publishing for data other services need — the Order service publishes events; the Analytics service maintains its own read model derived from those events.
Observability in distributed systems: you need more than logs
Debugging a monolith: a request comes in, you find the log line, you follow the stack trace. In a distributed system, a single user action triggers calls across five services. The log lines are in five different streams. The failure might be in service three, but the error surfaces in service one.
🔍 Distributed tracing
Every request gets a trace ID at the entry point that propagates through every downstream call. Tools like Jaeger, Zipkin, or Datadog APM visualise the full request path — which services were called, how long each took, where it failed. Without this, debugging cross-service issues is archaeology.
📊 Structured logging with context
Every log line includes the trace ID, service name, and relevant business context. This lets you pull all log lines related to a single trace across all services in one query. Unstructured logs become unsearchable at distributed scale.
📈 Service-level metrics with RED
Rate (requests/sec), Errors (error rate), Duration (latency distribution) — per service, per endpoint. Set SLOs per service and alert on breaches. Without per-service metrics, you can't tell which service in a chain is causing a degradation.
Set up your observability stack before you split into services, not after. Adding tracing to a distributed system already in production is painful. Adding it to a monolith before extracting services means every new service is observable from day one.
Migrating from monolith: the strangler fig pattern
The most common situation we encounter: teams with an existing monolith who want to gradually move toward service-based architecture without a risky big-bang rewrite.
The strangler fig pattern: build new functionality as separate services from the start, and gradually extract existing functionality piece by piece. A reverse proxy sits in front of both the monolith and new services, routing requests to the appropriate destination. Over time, more routes point to new services and fewer to the monolith.
Extraction sequence guidance: start with the seams — functionality that already has clear boundaries (email sending, PDF generation, payment processing). Extract read-heavy services first — services that mostly read data are easier to extract than write-heavy services with complex transaction requirements. Move the database last — run the new service against the monolith's database initially, then migrate data ownership once the service boundary is stable.
Our decision framework
| Signal | Recommended architecture |
|---|---|
| Team size under 8 engineers | Modular monolith |
| Early-stage, still finding product-market fit | Monolith — iterate fast, refactor later |
| Components with very different scale requirements | Extract those specific components only |
| Multiple teams, independent deploy cadences | Microservices per team domain |
| Compliance or data isolation requirements | Service separation where required |
| Inherited distributed system that's painful | Consider selective consolidation, not full rewrite |
The honest take
Most startups that choose microservices early do so for the wrong reasons — prestige architecture, future-proofing against hypothetical scale, cargo-culting what large companies do. Those companies have hundreds of engineers and years of operational tooling. They also started as monoliths.
The most expensive engineering decision we've seen early-stage companies make is building a distributed system before they've validated what they're distributing. A monolith that scales to millions of users is not a failure. Shopify ran on a monolith for years. Stack Overflow still does. The goal is shipping software that works.
